
AWS bills Athena as a serverless, interactive query service for your S3 objects. Athena is a pay-by-the-query service built on top of a popular distributed SQL engine Presto. Athena makes it easy to get started exploring your datasets and supports a variety of file formats. Athena also has ODBC and JDBC support so you can use your BI or SQL tool of choice. In addition to your run-of-the-mill big data queries, you can perform spatial queries. Athena supports the following geometry data types
- Points
- Line
- Multi-line
- Polygon
- Multi-polygon
With a bunch of geospatial functions
- ST_POINT
- ST_LINE
- ST_CONTAINS
- ST_INTERSECTS
- ST_BUFFER
- and many more
Athena spatial queries support WKT (Well-known Text) and JSON formats. Note: the JSON must be in the ESRI format as opposed to open geojson. Presto supports open geojson so I’m hoping Athena eventually does too. We’ll be working with two files. Neither one fits in the big data category, but they make for a tidy example. The first is a tab-delimited list of zip code centroids/points. The other is pipe-delimited WKT file of the 50 US states abbreviations and their polygons. Let’s start by creating the required schemas for both files followed by a preview of the data. Declaring Athena schemas should look familiar to Hive and Presto users. You can also use an AWS Glue Crawler to create your schemas if you prefer.
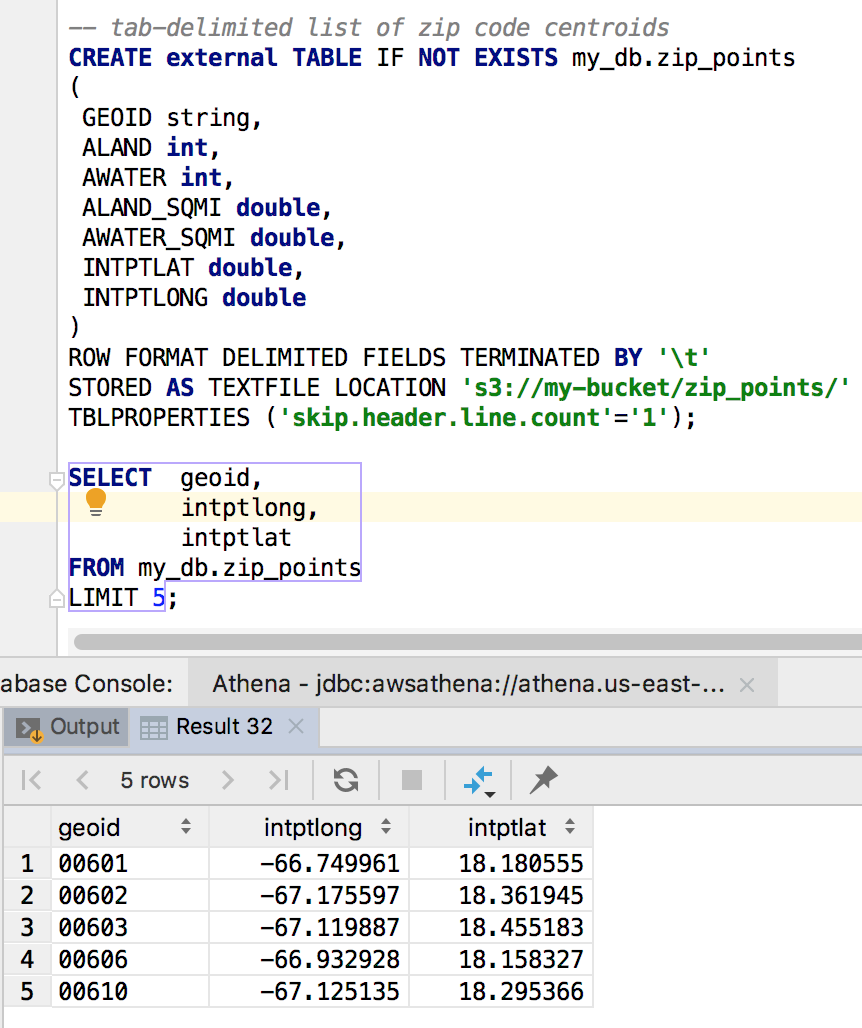
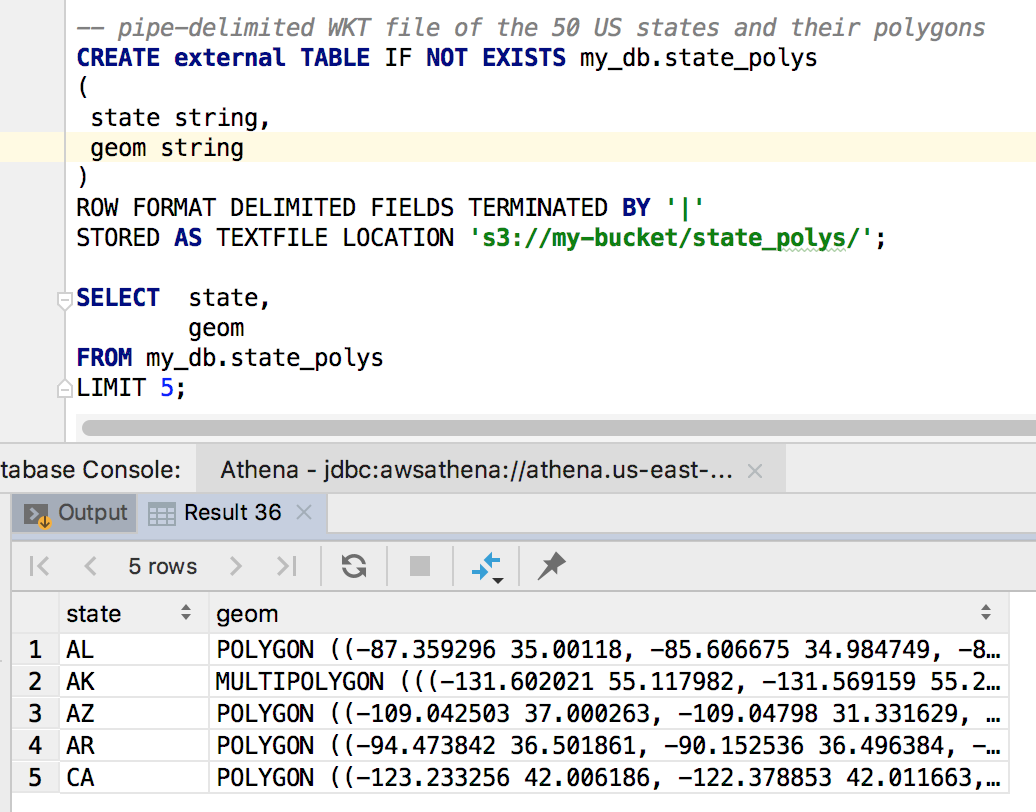
The schema definitions are pretty straightforward for us. Basically, we just have to specify data types, delimiters and where our data resides. We’re now ready to query our data. Let’s say we’re curious to know how many zip codes are in each state.
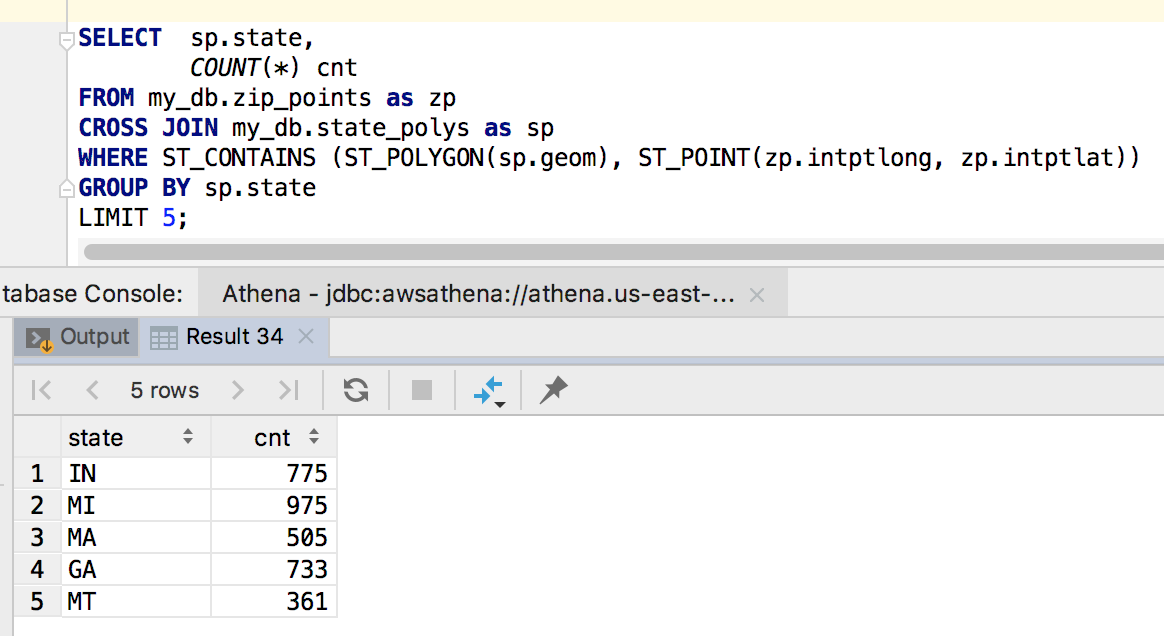
The magic is in the Where clause. State polygons and zip code points are created and ST_CONTAINS does the heavy lifting of figuring out which zips are IN each state.